鍋田辞書タイ語データ Ver 2.0(2014/6/24)
最終更新日 2014.6.24
ダウンロード鍋田辞書タイ語データ Ver 2.0(2014/6/24)ZIPファイル(タイ辞書 フリー) オンライン鍋田辞書タイ語 データ更新 Ver 2.0(2014/6/24) WEBで検索可。
特徴
無料。
発音記号付き。必要があればひとつの見出しに何個でも複数の発音記号を記述。
無料の発音記号付きタイ日辞書としては最大級でおそらく現時点最大。
ずっとタイ国内で作成。
他に似た辞書が存在しないオリジナルデータ。
タイ日と日タイの両方対応で、両方とも自動変換ではなく手作業で作成。
タイ日と日タイは検索時に切り替える必要がない。
タイの国語辞典であるタイ語・タイ語辞典を参照して作成。(ある時期からですが)
同じデータの検索サイトも用意してありWEBブラウザでオンライン検索が可能。
まだ作り続けています。
履歴
対応OS
対応フォント
対応ソフトウェア
読み間違いパターンが発生しない発音記号
「シンハー・コム」 なのか「シンハーク・ホム」 なのか分からなくなってしまいます。漢字のふりがな
多義語の別の意味
同義語、関連用語
直訳
ライセンス
鍋田辞書タイ語データの登録方法(リードオンリーデータとして) 鍋田辞書タイ語データの登録方法(編集可追加可データとして) 鍋田辞書のタイ語対応
鍋田辞書ホームに戻る
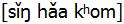 と表しています。
と表しています。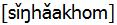 となり、どこで区切るかにより複数の読み方ができてしまいます。
となり、どこで区切るかにより複数の読み方ができてしまいます。